Queues in JS interviews
It's 2025 and JS still doesn't have built-in queues. This can be an issue in coding interviews, so, in this post, I'll go over the most practical workarounds.
I dealt with this issue myself while writing Beyond Cracking the Coding Interview, which goes over many problems that require queues, including:
- Graph problems about distances and shortest paths. Queues are used in BFS.
- Tree problems involving level-order traversals.
- Problems requiring monotonic queues, which use a normal queue under the hood (see the free Monotonic Stacks & Queues online chapter of BCtCI).
The book is in Python, but we also translated all the solutions to C++, JS, and Java, so we had to figure out how to translate all those solutions to JS.
If you know of any better workarounds, please let me know!
At the end, I'll also talk about double-ended queues (deques) and heaps, which are in a similar situation.
Option 1: Assume a queue exists
In an interview, the most important thing is to not waste time, so the most practical option may be to say something like:
Since JS doesn't support queues natively, can we assume that we have access to one with the typical push and pop methods working in constant time?
This option doesn't put you at a disadvantage relative to other languages.
If you are in an interview where your code must run, it's probably still a good idea to leave the queue implementation until the end, and focus on solving the core logic first. You can say:
If there is time at the end, I can circle back and implement it.
Option 2: Manual queue implementation
If you must implement the queue yourself, this is the most concise JS implementation I've seen.
It follows the classic linked-list implementation, but instead of:
- Defining a
Nodeclass - Defining a
Queueclass - Initializing a variable of that class
It all gets compacted into a single block by leveraging objects.
const queue = {
back: null,
front: null,
push: function (value) {
const node = { value: value, next: null };
if (this.back) this.back.next = node;
this.back = node;
if (!this.front) this.front = node;
},
pop: function () {
if (!this.front) return null;
const node = this.front;
this.front = node.next;
if (!this.front) this.back = null;
return node.value;
},
};
Still, it's easy to mess up the pointers if you're not careful, so I'll list other options below.
Thanks to veganaiZe on Discord for this implementation.
If you want to learn to implement a linked-list queue from scratch, check out the Linked-List-Based Queue problem from BCtCI online (it's free, but behind a login wall).
Option 3: Use arrays and shift
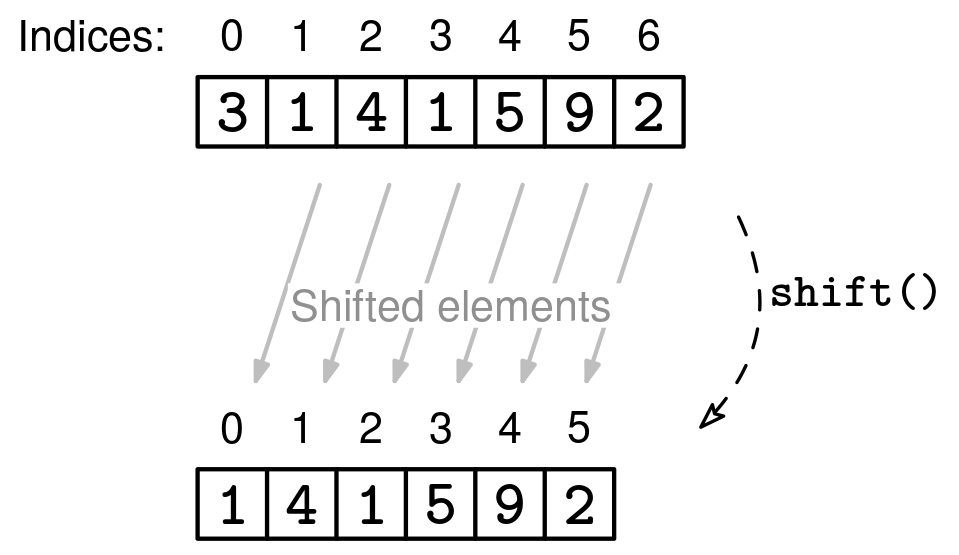
JS arrays have a push() method to add to the end in amortized constant time -- that's half of a queue.
They also have a shift() method to remove from the front, but the problem is that it USUALLY takes linear time, not constant time.
As the theory goes, removing from the front of an array takes linear time because it requires shifting all the elements after it (unlike in linked lists):
For example, this increases the worst-case runtime of a level-order traversal in an n-node binary tree from O(n) to O(n^2), and a BFS in a graph with V nodes and E edges from O(V + E) to O(V^2 + E).
I say USUALLY because it appears that SOME JS engines may be doing some optimizations behind the scenes to improve the shift() time.
Here's a quote from Array.shift optimizations in Firefox's JS Engine:
I was working on a codebase that ran into this bottleneck [array shifts], but what perplexed me was how in Firefox it ran almost instantly while in Node / Chrome it took seconds to complete.
What does that mean for interviews?
As of 2025, I think the "conventional wisdom" is that popping from the front of an array takes linear time, so you may get penalized for using shift() in an interview. What matters is what the interviewer believes.
If you choose to stick with arrays and shift(), you can try explaining to the interviewer something like:
I'm aware that shift usually takes linear time because it requires shifting all the elements after it, but I've seen that some JS engines do optimizations to improve the time. If I didn't have access to an engine like that, I would implement my own queue using a linked list.
Remember, what matters is showcasing your knowledge of big O analysis and of your programming language.
Option 4: Use arrays, but never shift
If you are implementing a BFS or a level-order traversal, you can simply never pop elements out of the queue. Instead, you can use a pointer to track the front of the queue. Instead of popping, we increment the pointer.
For reference, here is the straightforward BFS using shift():
// BFS using shift(), potentially slow
function bfs(graph, startNode) {
const queue = [];
const distances = new Map();
queue.push(startNode);
distances.set(startNode, 0);
while (queue.length > 0) {
const node = queue.shift();
for (const neighbor of graph.get(node)) {
if (!distances.has(neighbor)) {
queue.push(neighbor);
distances.set(neighbor, distances.get(node) + 1);
}
}
}
return distances;
}
And here is how we adapt it by never popping. We increment the front pointer instead of popping the queue. As you can see, the changes are minimal:
function bfs(graph, startNode) {
const queue = [];
const distances = new Map();
let front = 0; // Index in `queue` representing the front of the queue
queue.push(startNode);
distances.set(startNode, 0);
while (front < queue.length) {
const node = queue[front];
front++; // Increment pointer instead of shift()
for (const neighbor of graph.get(node)) {
if (!distances.has(neighbor)) {
queue.push(neighbor);
distances.set(neighbor, distances.get(node) + 1);
}
}
}
return distances;
}
This approach uses more space, but in the case of BFS and level-order traversals, it doesn't affect the asymptotic complexity. Whether popping or not, the worst-case size for the queue is O(n), where n is the number of nodes in the graph or tree. In addition, there are usually other data structures involved in a graph traversal that also take O(n) space, like the distances map. If the queue is not the bottleneck in the first place, we can use this approach.
A caveat: There can be cases where this approach is not a good idea. This is especially the case for data structure design problems, where we want the space complexity to be proportional to the number of elements in the data structure, not the number of elements that have ever been added to the data structure.
For example, if the problem asks us to implement a Queue data structure, using an array and never shifting would be a terrible approach. The linked-list implementation or the classic two-stack implementation would be better choices.
Option 5: Import a Queue package
The interviewer may be okay with you importing third-party packages to supplement the shortcomings of JS. They may prefer this over simply "assuming a queue exists".
If you want to go that route, here is a suitable package: yocto-queue.
Then, you can write:
import Queue from "yocto-queue";
const queue = new Queue();
queue.enqueue(3);
queue.dequeue();
// ...
So, which option is best?
Keep two factors in mind:
- What are you most comfortable with? The goal here is to not be at a disadvantage relative to other languages.
- What does the interviewer want? It's probably best to check with them (you can get communication points by asking proactively).
In any case, you can turn this shortcoming of JS into an opportunity to showcase your knowledge of big O analysis, about data structures, and about JS.
Double-ended queues
Of course, JS also doesn't have built-in double-ended queues (like the deque in Python).
Fortunately, they are less common than queues. They are used, for instance, in the Sliding Window Maximum problem.
Let's revisit our options for deques:
- Assume a deque exists: Your best option if the interviewer is okay with it.
- Manual deque implementation: Not recommended, as it requires a doubly-linked list, which is tricky to implement.
- Use arrays and
shift()andunshift(): Could work if you justify it to the interviewer. - Use arrays, but never shift: It doesn't work if the
frontvariable starts at0and you need tounshift(). To make it work, you need to pre-allocate as much space as you will need for front pushes, and then start thefrontpointer after that. - Import a Deque package: Here is a suitable package: @datastructures-js/deque (see the Examples for usage).
Heaps
Heaps (also known as priority queues) are in the same situation as queues and deques. Heaps are fairly common in coding interviews, as they are closely related to sorting. You can find the list of heap problems in BCtCI here: Heaps (they are free, but behind a login wall).
Let's revisit our options for heaps:
- Assume a heap exists: Your best option if the interviewer is okay with it. Implementing a heap from scratch could be a question in itself, so you are generally not expected to implement your own if other languages can just use a built-in heap.
- Manual heap implementation: Not recommended, as it requires implementing the bubble up/down logic. You can find the full heap implementation walkthrough from BCtCI here: Implement a Heap.
- Import a heap package: Here is a suitable package: heap-js (see the Examples for usage).
- Try non-heap solutions: Some problems where you'd typically use a heap can be solved efficiently by sorting or by using Quickselect. For instance, in the classic Smallest K Values problem, Quickselect is faster than a heap.
If you know of any better workarounds for any of these data structures, please let me know!
Want to leave a comment? You can post under the linkedin post or the X post.