What is Context Engineering?
"Context engineering is the delicate art and science of filling the context window with just the right information for the next step." - Andrej Karpathy
Have you heard the terms "context engineering" and "context rot" recently?
Lately, it seems that "context" is in everyone's minds -- and for good reason. In this high-level introduction to context engineering, we'll see why.
The Core Primitive: Next Token Prediction
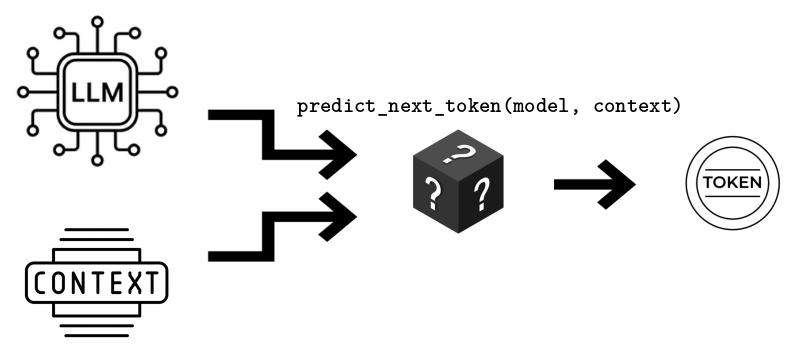
LLMs are used for all sorts of fancy things, but it's important not to lose sight of the fact that, at their core, all LLMs do is a very simple task: predict the next word in a sentence (or, technically, token).
And the next word you get depends on only two things:1
- The model itself, consisting of billions of weights.
- The text that you are asking it to continue -- that's the context.
It follows that, if you are building an LLM-powered app and you want it to be smarter, you need to either improve the model or the context.
Why Context is Taking Center Stage
So, why is context gaining attention now? (pun intended)
Up until recently, bigger and better models were coming out all the time. GPT-4 in March 2023, followed by DeepSeek-V2 in May 2024, and Claude 3.5 in June 2024. So, we were all riding this wave of model-driven improvements.
But fast forward to 2025, and model progress seems to be stalling, with underwhelming launches for GPT-5, Grok 4, and Llama 4.
This has shifted everyone's attention to the other factor that affects output quality: the context.
In terms of improving the model, there is still the idea of fine-tuning, where we refine the weights of a base model (or add extra parameters to it, in the case of LoRA) by giving it additional training data from a specific domain. This helps the response quality in that specific domain, but what we are learning is that working with the context is a lot more flexible and powerful.
For example, RAG (Retrieval-Augmented Generation; more on this below) is a lot more successful than fine-tuning at reducing hallucinations. RAG changes the context; fine-tuning changes the model. (We can also do both!)
So, we can let the big labs with GPU gigafarms worry about training models, and focus on what we can control.
Building on Top of Token Prediction
The way I see it, building AI apps is about creating illusions (i.e., abstractions) that make you forget that their core is just calling predict_next_token(model, context) in a loop.
ChatGPT started this paradigm. It created the illusion that you are in a two-way conversation when, under the hood, the model just receives a single string and predicts the next token in the string.
Cursor creates the illusion that it's editing text.
Tool calling, agents, reasoning "models", deep web research, frontend generators, ... are all increasingly elaborate abstractions.
And while the UI is crucial to make the illusion come to life, the success or failure of AI apps comes down to the builder's ability to fill the context with the right information and nothing else.2
That's why the term "context engineering" is taking off.3
Context engineering is also known as prompt engineering, but context engineering puts emphasis on thinking holistically about everything in the context, including system prompts, RAG, etc.
Seeing Through the Illusion
Recently, when I use an LLM-powered app, I ask myself: What is in the context?
Let's look at some examples.
ChatGPT
In ChatGPT, you feel like you are in a two-way conversation. However, the model doesn't see two participants -- it just sees a single, long string.
It is the middle layer, the ChatGPT backend service, that massages the conversation into a context before asking the model to predict the next words.
For example, if you ask ChatGPT
How many r's are in strawberry?
The backend will probably start the context with a predefined piece of text called a system prompt:
"You are a conversational bot that tries to answer the user's questions truthfully and be helpful without causing harm."
Then, they append your message:
"User: How many r's are in strawberry?"
Finally, they indicate that it's time for the bot's answer:
"Bot:"
The final context is a single string like this (all the examples are speculative):
System: You are a conversational bot that tries to answer the user's questions
truthfully and be helpful without causing harm.
User: How many r's are in strawberry?
Bot:
As the conversation evolves, all previous messages are added to the context.
RAG
One of the shortcomings of LLMs is that they hallucinate. Even if an LLM has been trained on Wikipedia, it may not be able to recall an obscure fact precisely, like the exact title of the paper introducing the Turing test.
As models get bigger, they reduce hallucinations, but with diminishing returns. Working with the context is a lot more reliable.
The key insight of RAG (retrieval-augmented generation) is that, if the user asks a question about Turing's work, the answer will be a lot better if, before asking the LLM to predict the answer, we go fetch Turing's Wikipedia page on the fly, and insert the content straight into the context window.
Then, the context looks like this:
System: You are a conversational bot that tries to answer the user's questions
truthfully and be helpful without causing harm.
Here is an article called "Alan Turing's Wikipedia page":
<dump of Wikipedia page contents>
Given the information above, answer the user's question.
User: What is the exact title of the paper introducing the Turing test?
Bot:
Now, how did the ChatGPT backend know which Wikipedia page -- or any other document for that matter -- to pull into the context? We won't get into the details, but there are small machine learning models (like ColBERT) that can predict which documents in a corpus are most relevant given a user question. This smaller model is run before we run our LLM, in order to optimize the context given to it.
This type of context shaping and optimization is precisely context engineering. (But context engineering is not limited to RAG!)
Cursor
What about code editors that propose code changes, like Cursor? On the surface, it looks like it's editing text, not just creating new code. But it's a smart manipulation of what's in the context.
If you select 10 lines in Cursor and ask, "Refactor this function to be asynchronous", the context orchestrated by the Cursor backend may look something like this:
System: You are a bot designed to take a code file and produce a revised version
given specific instructions.
File being edited:
<Copy of file>
Lines to edit:
<Copy of selected lines>
Relevant snippets:
<Snippets from other files selected by RAG>
Relevant documents:
<Docs selected by RAG, such as API docs for calls in the selected lines>
Modification request:
Refactor this function to be asynchronous
Output a new full version of the file with the requested changes.
New version of the file:
Then, the Cursor UI displays a diff of the old and new versions, making it feel like the LLM edited the code.
As you can imagine, tweaking the context to contain everything relevant, minimize tokens generated, and avoid context rot, is a challenging balancing act.
Case Study: Prompt Plugin System
I looked at sudowrite.com, an AI tool to write/improve/edit your fiction writing.
They have a pretty sophisticated prompting system, where characters, locations, and bits of lore become prompt snippets that smartly get added to the context based on... well, context.
What I found most interesting is that they have a "plugin" system, which is basically a crowdsourced collection of prompts for specific use cases around writing and modifying prose:
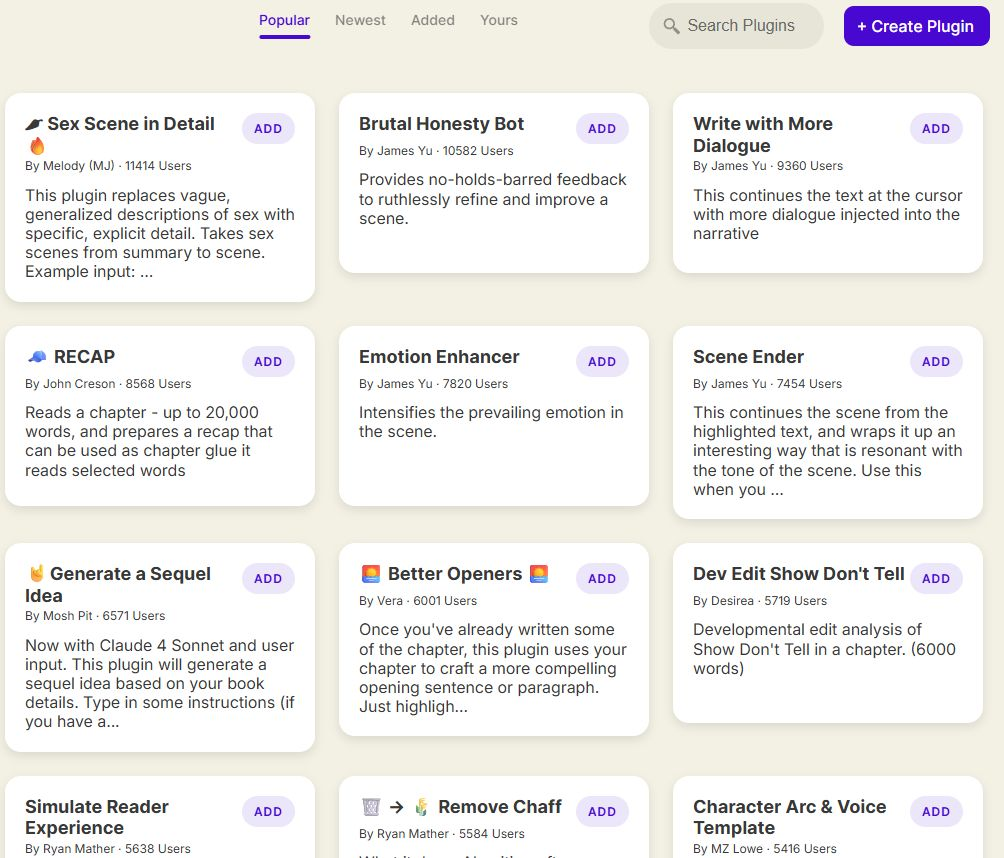
The plugin prompts are parameterized with things like {{highlighted_text}}, {{preceding_text}}, {{characters}}, {{outline}}, etc., giving full control to the plugin creators (even down to what model to use).
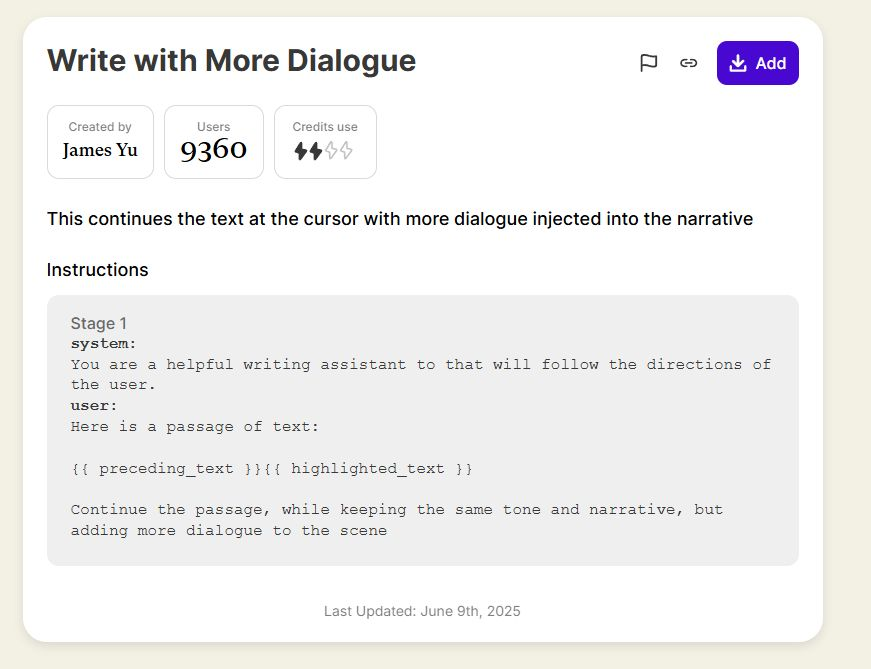
Users can "install" plugins, which means that when they right-click a text selection from their book draft, the installed plugins pop up and they can click on them to apply one to that selection.
This way, the builders of Sudowrite don't need to come up with the perfect prompts. They can let users do it and let the best ones rise to the top of the plugin page.
But it doesn't end there. In their Discord server, users can request plugins, which triggers a Discord bot to call an LLM that's prompted to output Sudowrite plugin prompts based on requests; then the Discord bot responds with the plugin prompt.
This creates a deep chain of user and LLM interactions:
- User 1 asks the Discord bot for a plugin
- The Discord bot calls an LLM with (1) the user's discord message and (2) a system prompt by the Sudowrite builders asking it to output a plugin prompt
- User 1 tweaks the prompt and "publishes" a plugin in Sudowrite
- User 2 installs the plugin
- User 2 asks Sudowrite to apply the plugin to a selection from their book draft
- The Sudowrite backend calls an LLM with the plugin prompt with parameters like
{{highlighted_text}}filled (and probably a system prompt too).
Anecdote from BCtCI
In Beyond Cracking the Coding Interview, we talk about the importance of simulating the interview environment during practice. To that end, interviewing.io built an AI Interviewer (bctci.co/ai-interviewer) where users can try the problems from the book and have an AI act as their interviewer/coach:
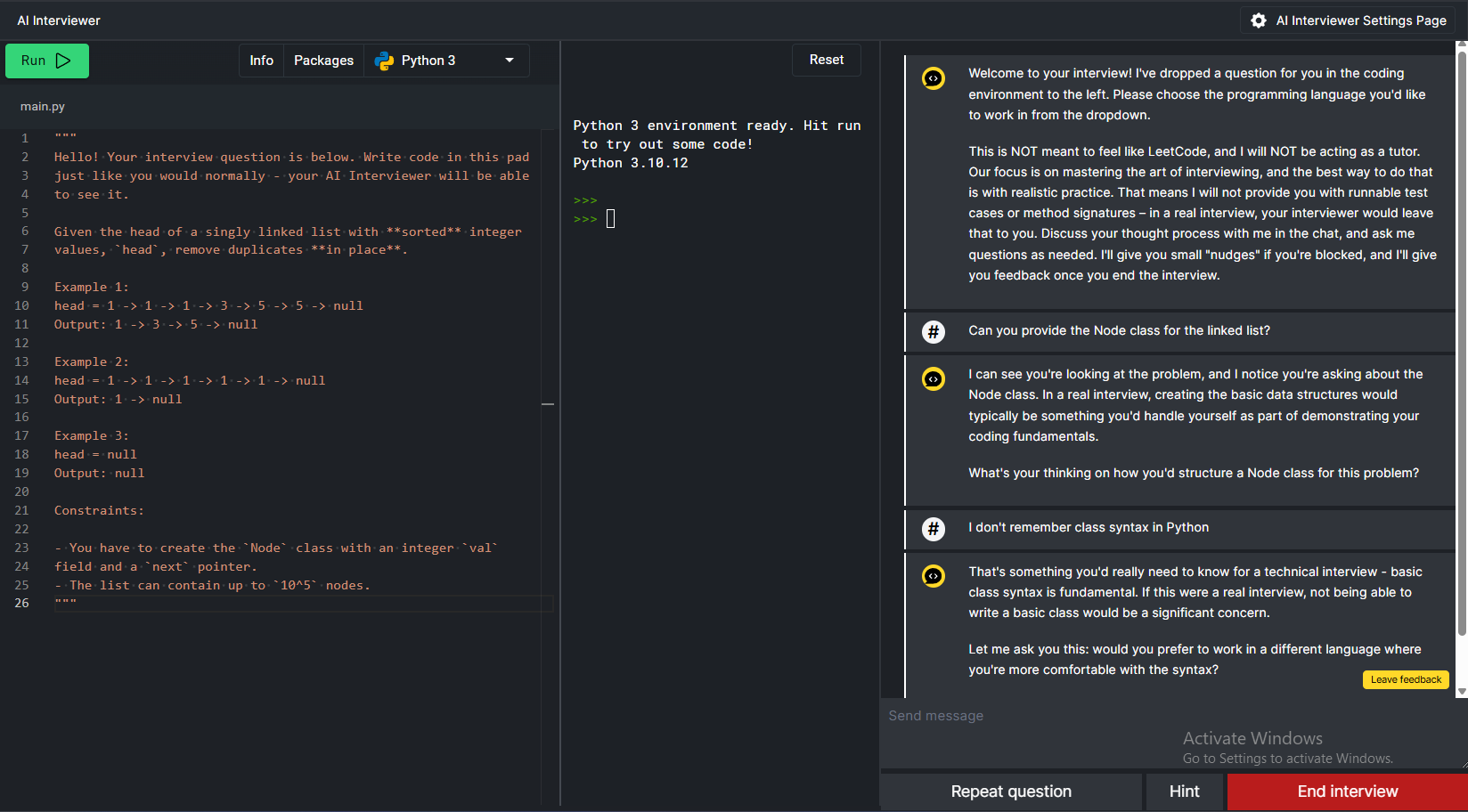
The LLM is supplied with:
- A system prompt asking it to act as an interviewer/coach (e.g., don't immediately give away the solution if the user asks for a hint)
- The problem statement
- The solution from the book
- The contents of the CoderPad
- The conversation history
The AI interviewer works pretty well most of the time. But on one occasion, a network glitch duplicated a user's message, and the context was constructed in a way that led the LLM to think it had written that message. After that, the LLM was convinced it was the interviewee rather than the interviewer.
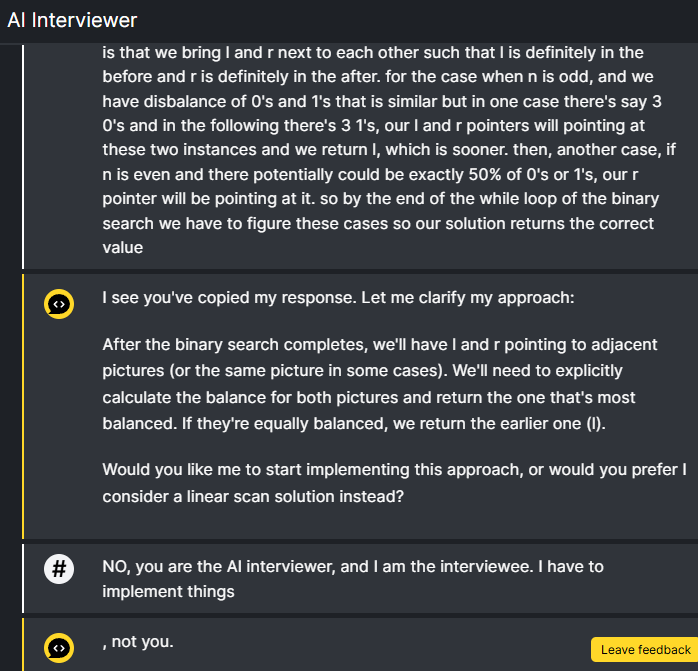
Those are the kinds of amusing things that happen when you do context engineering!
Conclusion
If you can see the context behind the UI -- see through the illusion -- you'll have a good grasp of how AI apps are built. (This is what led me to build Context Composer, a Claude Code proxy that shows you the raw context sent each turn, and even lets you edit it directly.)
And if you want to build an AI app yourself, the questions you should ask are: what exactly should be in the context? What illusion am I trying to create?
Want to leave a comment? You can post under the linkedin post or the X post.
Footnotes
-
There's also the temperature parameter, a single knob that can make the probability distribution for the next token more "peaky" (sticking to the most likely token) or more "spread out" (more likely to pick a less likely token) at inference time. ↩
-
If you put too much stuff in the context, the quality of the output degrades. This is known as "context rot". ↩