Wall Game DB Design
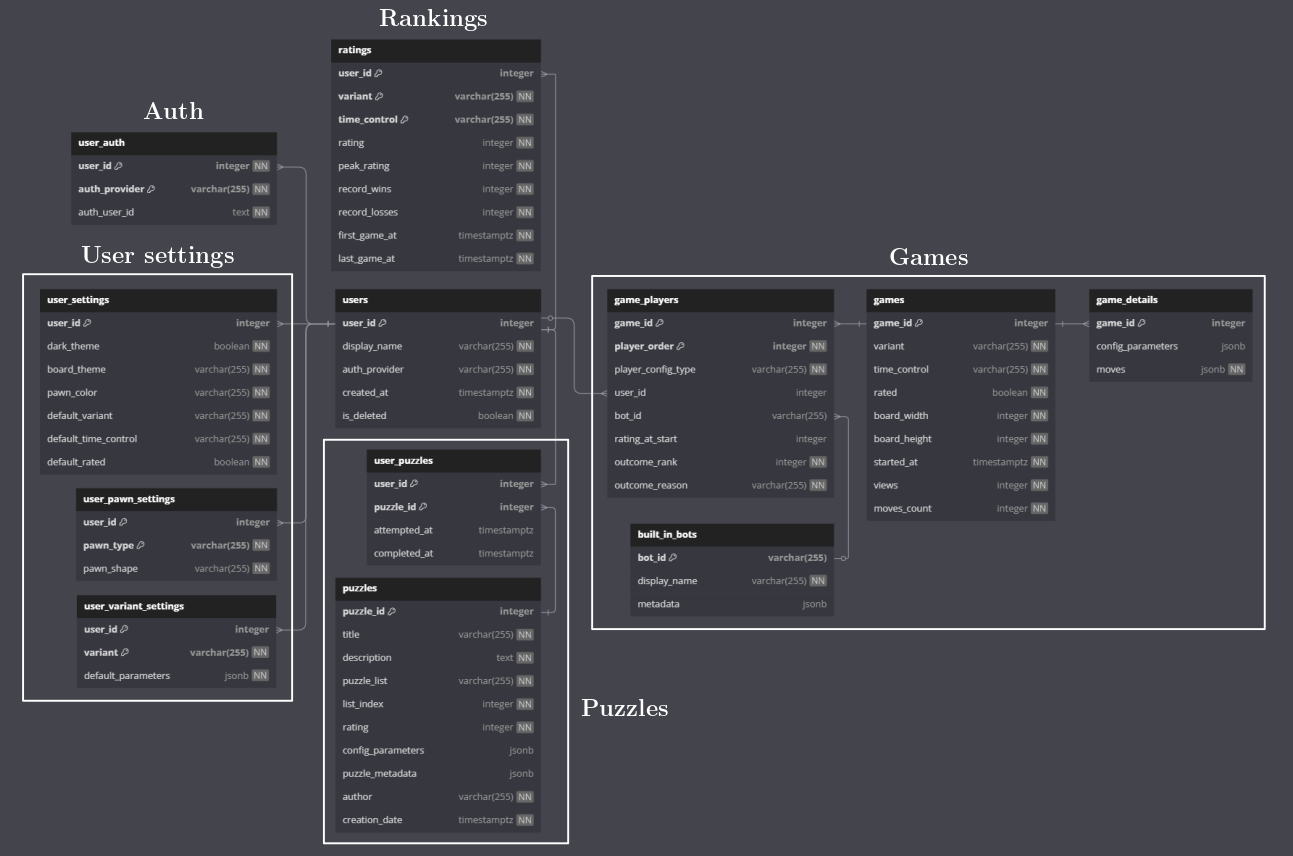
This blog post documents the initial design for the DB schema for the Wall Game, with commentary on the design choices.
I haven't tested any of the SQL. The site has not been built yet at the time of writing (March 2025). All the screenshots from the site are from a prototype made with v0.dev as explained in this post. As always, if you spot any mistakes or improvements, I'd love to know!
The DB is a PostgreSQL database, though I aim to keep the schema as dialect-agnostic as possible in case I want to migrate in the future. (You can see this post for a discussion on how I chose the tech stack.)
We'll start by designing all the tables, as shown in the diagram below, and then we'll write all the queries we need to support the frontend logic.
Users
This is the main users table:
CREATE TABLE users (
user_id INTEGER PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
display_name VARCHAR(255) NOT NULL UNIQUE,
capitalized_display_name VARCHAR(255) NOT NULL,
auth_provider VARCHAR(255) NOT NULL, -- e.g., kinde, auth0
created_at TIMESTAMPTZ NOT NULL DEFAULT CURRENT_TIMESTAMPTZ,
is_deleted BOOLEAN NOT NULL DEFAULT FALSE,
CONSTRAINT lowercase_display_name CHECK (display_name = LOWER(display_name))
);
Future-proofing auth-provider changes
I tried to future-proof it against auth-provider changes. The plan is to start using Kinde, which means that the only thing we need to store in the DB is a unique user ID provided by Kinde (it looks something like "kp_a1b2c3d4e5").
To avoid coupling, we don't want to use that as the user's primary id. A straightforward approach would be to put it in a separate field:
CREATE TABLE users (
user_id INTEGER PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
auth_user_id VARCHAR(255) NOT NULL UNIQUE,
...
);
However, in a migration, it may be tricky to coordinate the change of auth_user_id from the old auth provider to the new one. Instead, I decided to just indicate the auth_provider in the users table (e.g., "kinde") and put the auth_user_id in a separate table with primary key (user_id, auth_provider):
CREATE TABLE user_auth (
user_id INTEGER NOT NULL REFERENCES users(user_id) ON DELETE CASCADE,
auth_provider VARCHAR(255) NOT NULL,
auth_user_id TEXT UNIQUE NOT NULL, -- Kinde's user ID or other provider's ID
PRIMARY KEY (user_id, auth_provider)
);
This way, a user can have, e.g., a Kinde key and an Auth0 key at the same time, and we can switch from Kinde to Auth0 by changing the auth_provider in the users table from "kinde" to "auth0" (without deleting the Kinde key yet).
Handling unique usernames
We allow users to change their display name, and they are allowed to use uppercase letters, but, to avoid impersonation, we enforce that display name must be unique in a case-insensitive way.
We can think as the lowercase version of their display name as the "canonical" name, while the capitalized version is just an inconsequential styling choice. That's why we have both display_name and capitalized_display_name columns.
In general, the plan is to keep validation logic in the backend, not in the DB. However, I'm particularly concerned about uppercase letters slipping through to the display_name field, so I added the constraint:
CONSTRAINT lowercase_display_name CHECK (display_name = LOWER(display_name))
Encoding enum-like data
I've considered multiple ways of storing "enum-like" data like auth providers, time controls (which can only be "bullet", "blitz", "rapid", or "classical") or variants (which will start with only two options, but more will be added over time).
For example, if we have a column, my_enum, that can only have values "aa" and "bb", we could do:
- PostgreSQL's
ENUMtype. This is efficient and straightforward, but it would be a bit annoying to add new fields (e.g.,"cc"), as it would require a (small) schema change. It's also very Postgres specific.
CREATE TYPE my_enum_type AS ENUM ('aa', 'bb');
- A
VARCHARwith aCHECKconstraint. This would still require a schema change to add a new value.
my_enum VARCHAR(255) NOT NULL CHECK (my_enum IN ('aa', 'bb'))
- A "lookup table". We store the allowed values as the primary key in a separate table, say
allowed_values, and then have a foreign key constraint on themy_enumcolumn. This allows us to add new values without a schema change.
CREATE TABLE allowed_values (
value VARCHAR(255) PRIMARY KEY
);
...
my_enum VARCHAR(255) NOT NULL REFERENCES allowed_values(value)
...
- A "lookup table" with an auto-incremented integer primary key. Instead of making
"aa"the primary key directly, we could make the primary key an auto-incremented integer. This is more flexible and avoids string-matching logic and duplicating strings. However, this requires joins to get the actual names, complicating queries.
CREATE TABLE allowed_values (
id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL UNIQUE
);
...
my_enum INTEGER NOT NULL REFERENCES allowed_values(id)
...
- Use an integer, and have a convention between the backend and the DB about the mapping from those integers to the actual values. This is the most space- and time-efficient, but it's the most brittle.
In the end, I decided to KISS and use a plain string column, and just be careful when inserting values.
Rankings
ELO ratings are specific to a variant and time control, so we can't keep them in the users table.
CREATE TABLE ratings (
user_id INTEGER REFERENCES users(user_id),
variant VARCHAR(255) NOT NULL, -- "standard" or "classic"
time_control VARCHAR(255) NOT NULL, -- "bullet", "blitz", "rapid", or "classical"
rating INTEGER NOT NULL DEFAULT 1200,
-- Precomputed fields by the backend:
peak_rating INTEGER NOT NULL DEFAULT 1200,
record_wins INTEGER NOT NULL DEFAULT 0,
record_losses INTEGER NOT NULL DEFAULT 0,
last_game_at TIMESTAMPTZ NOT NULL DEFAULT CURRENT_TIMESTAMPTZ,
PRIMARY KEY (user_id, variant, time_control)
);
Optimizing the Ranking page
The final four columns in the ratings table are needed for the Ranking page (the First Game column in the prototype below will be replaced by Join Date):
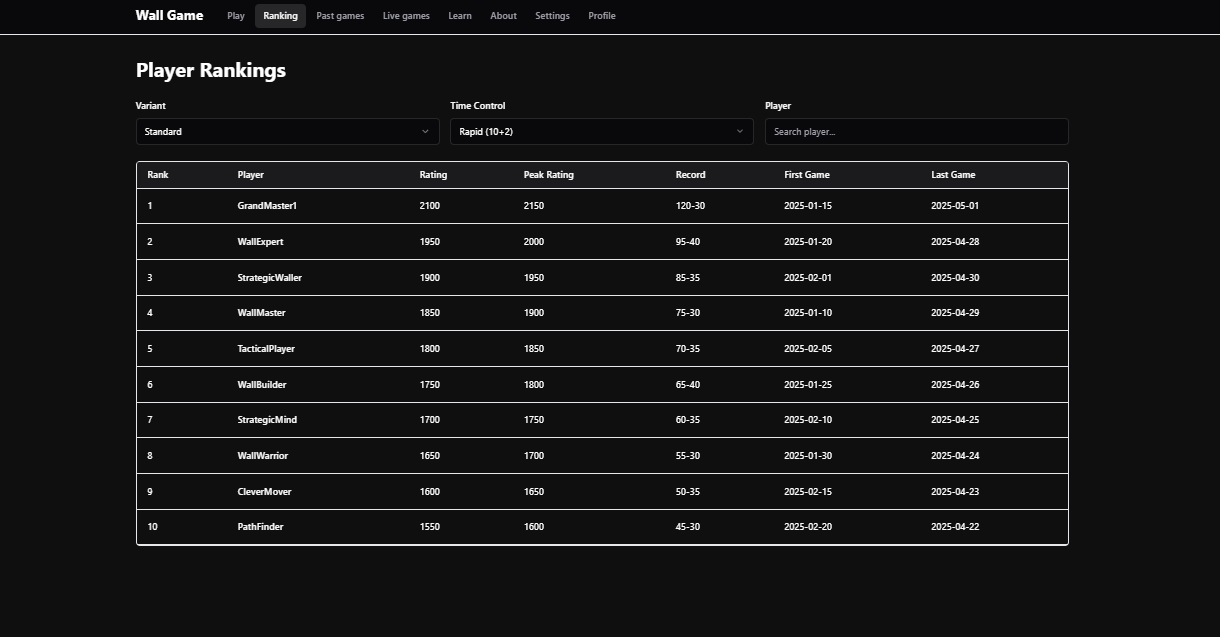
These columns are redundant, as they could be computed by aggregating information from the
games table. However, it would be expensive to, e.g., look through all the games
of a user to find its peak rating. Instead, the plan is to precompute these columns
in the backend and update them whenever a user finishes a game.
The downside of this approach is that the games and ratings tables may be in an inconsistent state. For example, if a game somehow disappears from the games table, a player may end up with a "3-0" record even though they only have two games in the DB. I think this is OK. First, it's not clear what should happen if a game disappears--it doesn't retroactively change the fact that the player played three games. Second, we can always run a one-off query to fix the precomputed fields.
Instead of having the backend compute these fields, an alternative approach would be to have a cron job that updates them periodically. However, when a user reaches a new peak rating, they probably want it to be reflected immediately in the Ranking.
Games
Games will only be stored in the DB when they are finished, which allows us to make more assumptions (all players joined, there is an outcome, etc.) and simplify the schema. The downside is that, if the server crashes, all on-going games will be lost. (I once mentioned this concern to a friend and he said, "But the server shouldn't crash." Fair point...)
CREATE TABLE games (
game_id INTEGER PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
variant VARCHAR(255) NOT NULL,
time_control VARCHAR(255) NOT NULL,
rated BOOLEAN NOT NULL,
board_width INTEGER NOT NULL,
board_height INTEGER NOT NULL,
started_at TIMESTAMPTZ NOT NULL,
views INTEGER NOT NULL DEFAULT 0,
-- Precomputed fields by the backend:
moves_count INTEGER NOT NULL DEFAULT 0
);
Optimizing the Past Games page
We split the game data into two. The main table, games, has all the "metadata" about the game, while the game_details table has the actual list of moves and configuration parameters (e.g., variant-specific parameters):
CREATE TABLE game_details (
game_id INTEGER PRIMARY KEY,
config_parameters JSONB, -- Variant-specific game configuration parameters
moves JSONB NOT NULL, -- Custom notation for all moves
FOREIGN KEY (game_id) REFERENCES games(game_id) ON DELETE CASCADE
);
The reason for the split is that the game details take a lot more space than the other fields, and the main use case for storing games is listing them on the "Past Games" page, which doesn't need the game details:
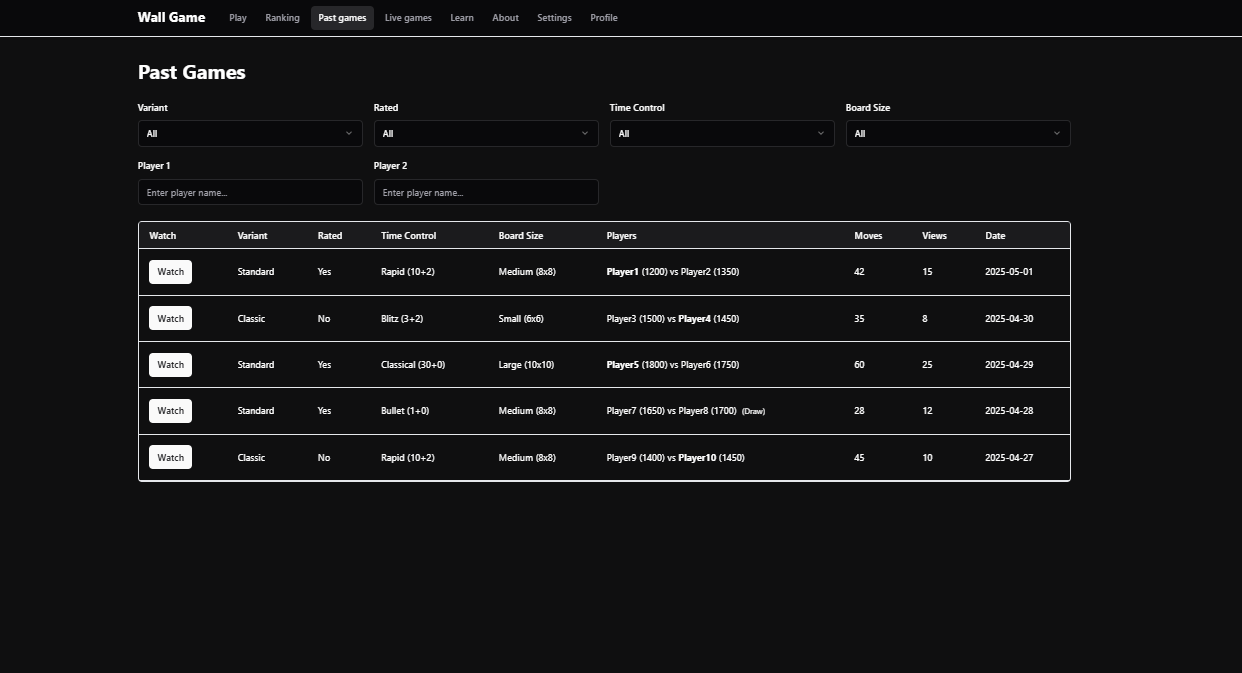
The query for this page can be based on the games table only. The game details only need to be brought in when the user watches a specific game.
I'm really not sure if this is worth it, though. This may be a premature optimization that adds unnecessary complexity (the two tables now need to be kept in sync and updated together in transactions).
Another interesting decision was whether to store the moves in a SQL moves table or as a JSON blob. I decided to go with the latter because I don't have any need for querying individual moves within a game or across games. We'll always want either all the moves of a single game, or none. One downside is that we need to precompute the moves_count column in the games table.
Game players
As you can see, the games table does not capture the players or the game outcome. The reason is that the number of players per game depends on the variant, so we couldn't simply have player1 and player2 columns. For the same reason, the outcome is not as simple as "P1 won" or "P2 won" or "draw". Instead, it makes more sense to think about per-player outcomes. Each player outcome consists of a placement and a reason. E.g., a player may have finished 3rd for the reason that the 4th player timed out.
The following table connects games and players:
CREATE TABLE game_players (
game_id INTEGER REFERENCES games(game_id),
player_order INTEGER NOT NULL, -- 1 for the 1st mover, 2 for the 2nd mover, etc.
player_config_type VARCHAR(255) NOT NULL, -- "you", "friend", "matched user", "bot", "custom bot"
user_id INTEGER REFERENCES users(user_id), -- NULL for non-logged-in users and built-in bots
bot_id INTEGER REFERENCES built_in_bots(bot_id), -- Only non-NULL for built-in bots
rating_at_start INTEGER, -- Rating at game start, NULL for custom bots
outcome_rank INTEGER NOT NULL, -- e.g., 1 for winner
outcome_reason VARCHAR(255) NOT NULL, -- "timeout", "resignation", "knockout", "agreement", "tie", "abandoned"
PRIMARY KEY (game_id, player_order)
);
As we discussed earlier, handling username changes is tricky. If you are watching a past game, do you want to see the current name or the name at the time of the game? In our case, we won't bother with historical names, so we don't need a player_name_at_the_time column. The same for the pawn color and shape they chose at the time. On the other hand, we do want to know their ELO at the time.
Bots
Let's discuss the workflow for built-in bots. Besides the main backend, there is a bot service responsible for making bot moves. The main backend stays focused on I/O tasks and doesn't hang on long computations.
The steps go like this:
- The user chooses the game parameters (e.g., the variant) and chooses to play against a built-in bot.
- The backend asks the bot service for bots available given the game parameters.
- The bot service responds with a list of bot names to display (e.g., "Easy Bot", "Medium Bot", "Hard Bot") along with their
bot_id's. - The player chooses a bot and the game starts.
- The backend asks the bot service for moves from the chosen bot by providing its
bot_id. - When the game ends, the backend uploads it to the DB. If the
bot_idis not in thebuilt_in_botstable, a new row is added:
CREATE TABLE built_in_bots (
bot_id VARCHAR(255) PRIMARY KEY,
-- Fields should not be changed after creation
-- e.g., "Easy Bot", "Medium Bot", "Hard Bot". Not unique. Uppercase allowed.
display_name VARCHAR(255) NOT NULL,
metadata JSONB -- metadata provided by the bot service (e.g., compilation flags)
);
The bot service is responsible for choosing and managing bot IDs. The idea is that they should identify a specific algorithm/implementation/binary/version. That is, if I train an improved version of the "Hard Bot", the display name can stay the same, but the bot_id should be different.
The backend and the DB don't need to know which bot_id's can play in which variants and things like that. The backend doesn't ask the DB for which bots are available--it asks the bot service. So, there is no variant column and such in the built_in_bots table.
Custom bots
Custom bots are not fully designed yet, but, for an initial design, we don't need a table for custom bots. When a user chooses to play against their own custom bot, the user is given a token to join the game from their bot client. The client only provides moves (as if it were a human), and does not have its own display name or bot id (to avoid having to deal with clashes with real users or built-in bots). The display name can always be "Custom Bot".
In a full-fledged custom bot system like the one on Lichess, custom bots are just like regular users (with some limitations). Anyone can list their bot, and then players can invite them to a game and they'll join just as if you invited a regular user. This is out of scope.
Puzzles
A puzzle is a game that has been setup to a specific situation where there is a good move (or sequence of moves) that the user must find. Here is Puzzle 10 from the first version of the site, wallwars.net:
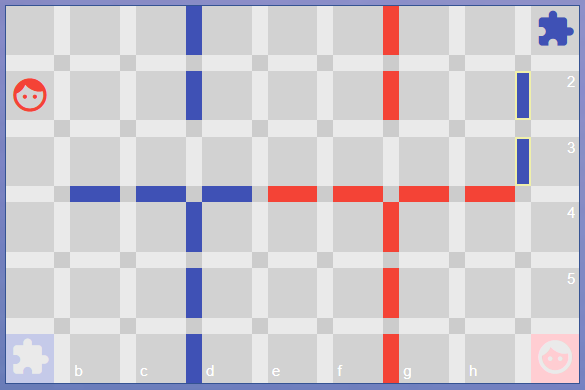
Here is the main puzzles table. The specific initial configuration (pre-existing walls and player positions) is part of the game parameters.
CREATE TABLE puzzles (
puzzle_id INTEGER PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
title VARCHAR(255) NOT NULL,
description TEXT NOT NULL,
puzzle_list VARCHAR(255) NOT NULL, -- "solo_campaign" or "puzzles"
list_index INTEGER NOT NULL, -- Position of the puzzle within its list, for ordering
rating INTEGER NOT NULL, -- Difficulty rating of the puzzle, in ELO
config_parameters JSONB, -- Puzzle setup (e.g., variant, pre-existing walls and player positions)
puzzle_metadata JSONB, -- Additional metadata about the puzzle
author VARCHAR(255) NOT NULL, -- Puzzle author (not a user)
creation_date TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
To track completions:
CREATE TABLE user_puzzles (
user_id INTEGER REFERENCES users(user_id),
puzzle_id INTEGER REFERENCES puzzles(puzzle_id),
attempted_at TIMESTAMPTZ, -- NULL if not attempted
completed_at TIMESTAMPTZ, -- NULL if not completed
PRIMARY KEY (user_id, puzzle_id)
);
A complication with the Wall Game (compared to, e.g., chess) is that there are often many moves that achieve the same effect. E.g., if there is a long 'tunnel' that is one row wide, putting any wall along the tunnel has the same effect of blocking it. There can be 100's of equally good moves in realistic situations. Thus, we cannot simply check whether the user finds the "correct" move.
Instead of "hard-coding" the solution, we can compare the user's move against the moves of a bot which is smart enough to solve the puzzle. If the bot scores the player's move as tangibly worse than its top choice, the move is considered wrong. The same bot also counters the player's moves. This goes on until the game ends (the player wins or draws) or until the user has made a predetermined number of moves (which can be specified in the puzzle_metadata). If necessary, we can experiment with fine-tuning the baseline AI to solve specific puzzles. We'll see.
For now, we don't support user-created puzzles.
User settings
The final tables stores the user settings.
CREATE TABLE user_settings (
user_id INTEGER PRIMARY KEY REFERENCES users(user_id),
dark_theme BOOLEAN NOT NULL DEFAULT TRUE,
board_theme VARCHAR(255) NOT NULL DEFAULT 'default',
pawn_color VARCHAR(255) NOT NULL DEFAULT 'default',
default_variant VARCHAR(255) NOT NULL DEFAULT 'standard', -- "standard" or "classic"
default_time_control VARCHAR(255) NOT NULL DEFAULT 'rapid', -- "bullet", "blitz", "rapid", or "classical"
default_rated_status BOOLEAN NOT NULL DEFAULT TRUE
);
CREATE TABLE user_pawn_settings (
user_id INTEGER REFERENCES users(user_id),
pawn_type VARCHAR(255) NOT NULL, -- "cat", "mouse", "goal", etc.
pawn_shape VARCHAR(255) NOT NULL, -- A sprite/icon identifier that the backend should recognize.
PRIMARY KEY (user_id, pawn_type)
);
CREATE TABLE user_variant_settings (
user_id INTEGER REFERENCES users(user_id),
variant VARCHAR(255) NOT NULL,
default_parameters JSONB NOT NULL, -- Variant-specific default parameters
PRIMARY KEY (user_id, variant)
);
Queries
The following queries power the functionality we need for the site.
Game showcase
The landing page shows a showcase from a past game, which autoplays the moves. This requires pulling a random game from the DB, including the moves.
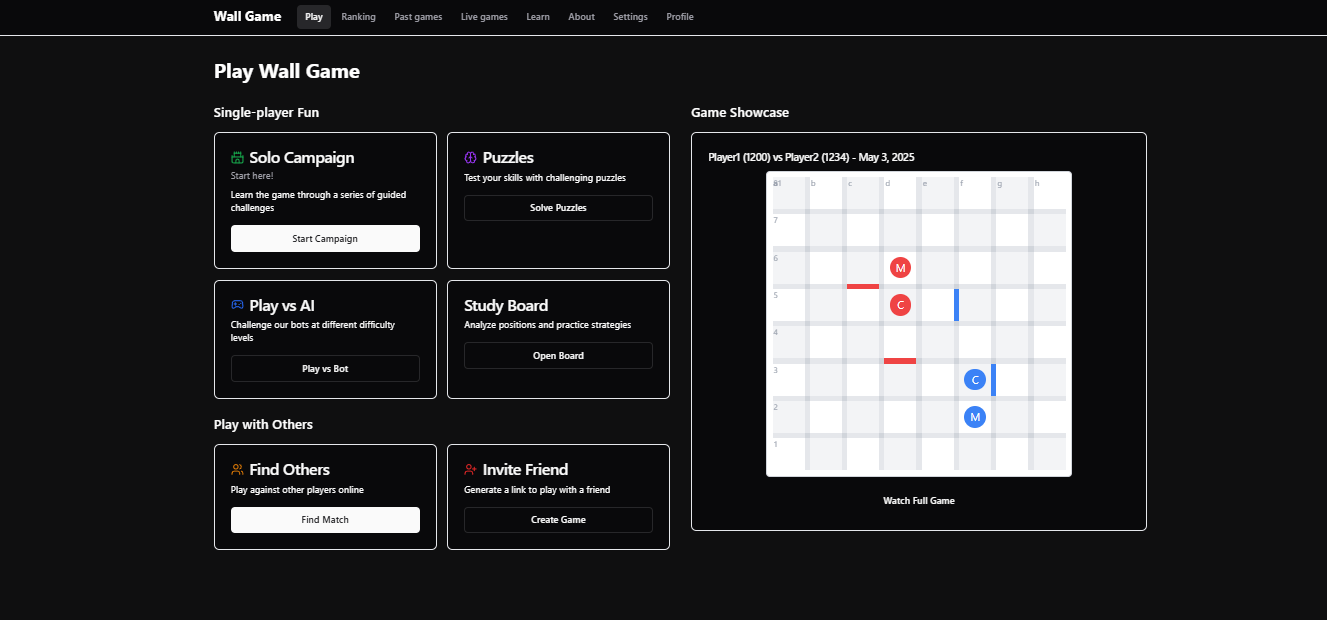
We can get it with this query:
SELECT g.game_id, g.variant, g.time_control, g.rated, g.board_width,
g.board_height, g.started_at, g.moves_count, gd.config_parameters,
gd.moves
FROM games AS g
JOIN game_details AS gd USING (game_id)
ORDER BY RANDOM()
LIMIT 1;
To reduce DB queries, the backend could send the same showcase game to multiple users.
Solo campaign & Puzzles
When the user goes to the 'Solo Campaign' page, they can see an ordered list of "levels" (i.e., puzzles) in order. Each level has a name, description, difficulty, and completion status.
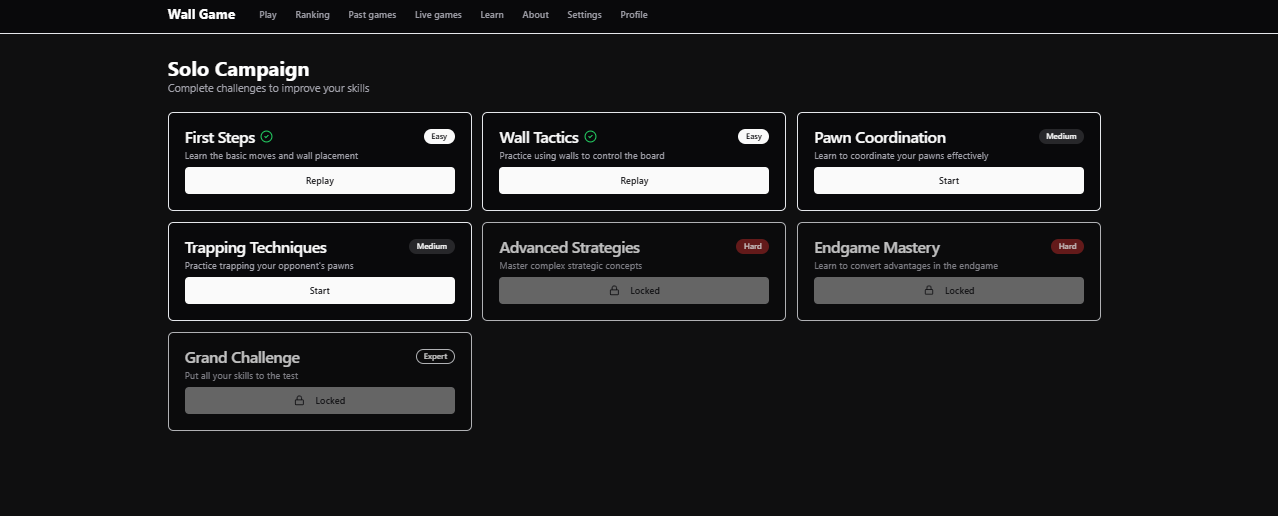
We can pull them with this query:
-- :user_id is the user's ID
SELECT p.puzzle_id, p.list_index, p.title, p.description, p.rating,
p.config_parameters, p.puzzle_metadata, up.completed_at
FROM puzzles AS p
LEFT JOIN user_puzzles AS up
ON p.puzzle_id = up.puzzle_id AND up.user_id = :user_id
WHERE p.puzzle_list = 'solo_campaign'
ORDER BY p.list_index;
The 'Puzzles' page is similar.
We include p.config_parameters and p.puzzle_metadata in the query so that, when the user clicks on a puzzle/level, we have everything we need to set it up and start playing.
Available games
Players can see a list of games in the matchmaking stage, where the user is waiting for an opponent.
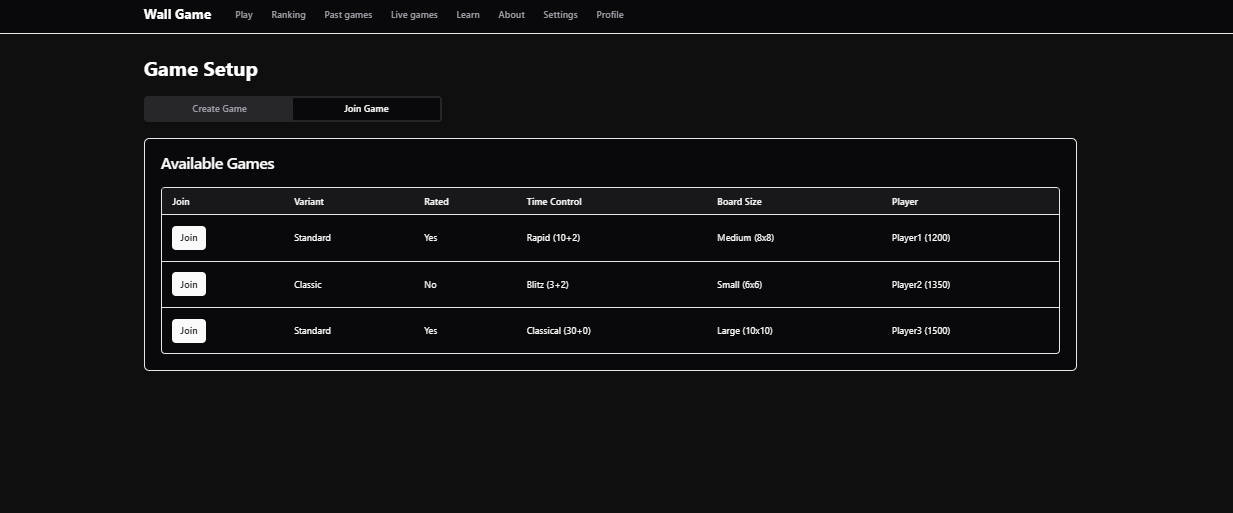
We won't use SQL for this. These games haven't finished yet, so they are not in the DB--only in the backend.
Implementing pagination and filtering
The 'Ranking' and 'Past Games' pages allow the user to essentially inspect the ranking and games tables, respectively, with pagination and filtering. This gives rise to a basic yet tricky software architecture question:
Suppose you have a full-stack app and there is a large table in the DB, which the user can browse in the frontend. We show the user 100 rows at a time, and they can navigate to the next or previous 100 rows. How do you implement this pagination? (We could ask the same about filtering.)
Assumptions:
- The table is not just static data; it gets updates over time.
- The rows must be shown to the user sorted by a specific column, say, 'rank'.
- The backend runs on a single server.
You have 3 main options for where to implement pagination:
-
At the DB level: this is slow, as it requires a DB round-trip every time the user wants to see a new 100-row block, but it guarantees the data is never stale and the backend can remain stateless. We can add a table index on the 'rank' column to speed up the query.
-
At the backend level: if the backend maintains a cached copy of the table (say, as an array), it can return the appropriate range of the array to the frontend, avoiding the DB. This introduces the problem of how to keep the backend's copy of the table always synced with the DB and sorted by 'rank'. For the former, the backend would need to do parallel updates to the DB and the cache. For the latter, if re-sorting on each update is too expensive, something like Redis could take care of it for us.
-
At the frontend level: whenever the user goes to the page, the backend sends the full table (or a big chunk of it), not just the first 100 rows (the backend either maintains a cached copy or queries the DB). This approach makes pagination the most responsive, involving no API calls, but it is also the most stale, as the data won't update until the user refreshes the page. In this case, whether the backend maintains a local copy or not only affects the initial load time.
Each approach has its pros and cons. It comes down to the numbers, like the number of rows, the size of each row, the frequency of updates, the duration of a round-trip, how often each feature is used, and so on.
Did I miss any other options?
Ultimately, there's no right answer, as it also depends on subjective factors like how much you care about user experience vs data freshness, or how much you care about adding engineering complexity.
The same decision about where to do pagination also comes up with row filtering and ordering. It can be done in the DB, backend, or frontend.
For our site, we'll start with the slowest but simplest solution (DB round-trip each time), and we'll optimize as needed.
Ranking
The 'Ranking' page consists of a set of filters and a table where rows are filtered by those filters.
The mandatory filters are 'Variant' and 'Time control'.
By default, the ranking shows the top 100 players for that variant and time control. We can use pagination to see more.
To fill in each row, we need the following data: rank, player, rating, peak rating, record wins and losses, user creation date, and date of the user's last game.
There is also an optional 'Player' search box. If filled with a player name and the player exists, it jumps directly to the page (100-block) containing that player. If the player does not exist, it shows nothing.
As mentioned, we'll implement pagination and filtering in the DB. We can add a table index on the display_name column to speed up the "player search" query:
CREATE INDEX ON users (display_name);
Here is the full query:
-- mandatory filters: :variant, :time_control, :page_number (1-indexed; for pagination)
-- optional: :player_name (if provided, overrides page_number)
WITH ranked AS (
SELECT r.user_id, u.display_name, r.rating, r.peak_rating, r.record_wins,
r.record_losses, u.created_at, r.last_game_at,
-- break ELO ties by oldest account
ROW_NUMBER() OVER (ORDER BY r.rating DESC, u.created_at) AS rank
FROM ratings AS r
JOIN users AS u USING (user_id)
WHERE r.variant = :variant AND r.time_control = :time_control
),
offset_value AS (
SELECT
CASE
WHEN :player_name IS NOT NULL THEN
COALESCE(
(SELECT ((rank - 1) / 100) * 100
FROM ranked
WHERE display_name = :player_name),
0
)
ELSE
(:page_number - 1) * 100
END AS value
)
SELECT * FROM ranked
ORDER BY rank
OFFSET (SELECT value FROM offset_value)
LIMIT 100;
We include deleted players in the ranking. They'll just show up as something like "Deleted User 23".
Past games
We already discussed the 'Past games' page in the Games section. All the filters have an "all" option which is the default:
- Variant
- Rated
- Time control
- Board size: selector with (small / medium / large / all). Games are grouped by board size according to width x height: "Small" (up to 36 squares), "Medium" (up to 81 squares) and "Large" (more than 81 squares).
- ELO: a numerical range (missing from the 'Past games' page screenshot)
- Time period: a date range (missing from the 'Past games' page screenshot)
- Two player filters: filling one gives you all games with that player. Filling both gives you all games including both players.
We also need pagination: we'll show up to 100 games per page and let the user navigate to the next/previous 100-block.
To fill in each row, we need the following data: variant, rated, time control, board width and height, names and ELOs of all the involved players (could be more than 2 depending on the variant), the number of moves, and the date when the game was played. We also need the game id in case the user wants to watch the game.
-- mandatory: :page_number (1-indexed; for pagination)
-- optional filters: :variant, :rated, :time_control, :board_size, :min_elo,
-- :max_elo, :date_from, :date_to, :player1, :player2
SELECT g.game_id, g.variant, g.rated, g.time_control, g.board_width,
g.board_height, g.moves_count, g.started_at,
json_agg(
json_build_object(
'player_order', gp.player_order,
-- TODO: check this line
'display_name', COALESCE(u.display_name,
CASE WHEN b.display_name IS NOT NULL
THEN b.display_name
ELSE 'Guest' END),
'rating_at_start', gp.rating_at_start,
'outcome_rank', gp.outcome_rank,
'outcome_reason', gp.outcome_reason
) ORDER BY gp.player_order
) AS players
FROM games AS g
JOIN game_players AS gp USING (game_id)
LEFT JOIN users AS u USING (user_id)
LEFT JOIN built_in_bots AS b USING (bot_id)
WHERE
(:variant IS NULL OR g.variant = :variant)
AND (:rated IS NULL OR g.rated = :rated)
AND (:time_control IS NULL OR g.time_control = :time_control)
AND (
:board_size IS NULL
OR (:board_size = 'small' AND g.board_width * g.board_height <= 36)
OR (:board_size = 'medium' AND g.board_width * g.board_height > 36 AND g.board_width * g.board_height <= 81)
OR (:board_size = 'large' AND g.board_width * g.board_height > 81)
)
AND (:date_from IS NULL OR g.started_at >= :date_from)
AND (:date_to IS NULL OR g.started_at <= :date_to)
AND (
-- Assumes that if :min_elo is NULL, :max_elo is also NULL
:min_elo IS NULL
OR EXISTS (
SELECT 1 FROM game_players AS gp_elo
WHERE gp_elo.game_id = g.game_id
AND gp_elo.rating_at_start IS NOT NULL
AND gp_elo.rating_at_start >= :min_elo
AND (:max_elo IS NULL OR gp_elo.rating_at_start <= :max_elo)
)
)
-- Handle player1 filter
AND (
:player1 IS NULL
OR EXISTS (
SELECT 1 FROM game_players AS gp1
JOIN users AS u1 USING (user_id)
WHERE gp1.game_id = g.game_id
AND u1.display_name = :player1
)
)
-- Handle player2 filter
AND (
:player2 IS NULL
OR EXISTS (
SELECT 1 FROM game_players AS gp2
JOIN users AS u2 USING (user_id)
WHERE gp2.game_id = g.game_id
AND u2.display_name = :player2
)
)
GROUP BY g.game_id
ORDER BY g.started_at DESC
OFFSET (:page_number - 1) * 100
LIMIT 100;
When the user selects a game to watch, we need to get the moves and configuration parameters, as well as the players' chosen pawn colors and shapes, which we can pull from the user_settings table:
-- :game_id is the ID of the game to watch
SELECT g.game_id, g.variant, g.time_control, g.rated, g.board_width,
g.board_height, g.started_at, g.views, g.moves_count, gd.config_parameters,
gd.moves,
json_agg(
json_build_object(
'player_order', gp.player_order,
'display_name', COALESCE(u.display_name,
CASE WHEN b.display_name IS NOT NULL
THEN b.display_name
ELSE 'Guest' END),
'rating_at_start', gp.rating_at_start,
'outcome_rank', gp.outcome_rank,
'outcome_reason', gp.outcome_reason,
'pawn_color', COALESCE(us.pawn_color, 'default'),
'pawn_settings', (
SELECT json_object_agg(ups.pawn_type, ups.pawn_shape)
FROM user_pawn_settings AS ups
WHERE ups.user_id = u.user_id
)
) ORDER BY gp.player_order
) AS players
FROM games AS g
JOIN game_details AS gd USING (game_id)
JOIN game_players AS gp USING (game_id)
LEFT JOIN users AS u USING (user_id)
LEFT JOIN built_in_bots AS b USING (bot_id)
LEFT JOIN user_settings AS us ON u.user_id = us.user_id
WHERE g.game_id = :game_id
GROUP BY g.game_id, gd.config_parameters, gd.moves;
Settings
When the user goes to the 'Settings' page, they can change the following settings, and this is stored in the DB:
- Display name
- Dark theme
- Board theme
- Pawn color
- Cat pawn shape
- Mouse pawn shape
- ... (one selector for each pawn type that appears in any variant)
- Default variant
- Default time control
- Default rated status
- Default parameters for each specific variant
We pull the settings with this query:
-- :user_id is the ID of the user whose settings we're retrieving
SELECT
-- General settings
us.dark_theme, us.board_theme, us.pawn_color,
us.default_variant, us.default_time_control, us.default_rated_status,
-- Pawn settings (as JSON array)
(
SELECT json_agg(
json_build_object(
'pawn_type', ups.pawn_type,
'pawn_shape', ups.pawn_shape
)
)
FROM user_pawn_settings AS ups
WHERE ups.user_id = us.user_id
) AS pawn_settings,
-- Variant-specific settings (as JSON array)
(
SELECT json_agg(
json_build_object(
'variant', uvs.variant,
'default_parameters', uvs.default_parameters
)
)
FROM user_variant_settings AS uvs
WHERE uvs.user_id = us.user_id
) AS variant_settings
FROM user_settings AS us
WHERE us.user_id = :user_id;
To guarantee unique usernames, a user can only change it to a username that does not appear in the DB. We can check this with this query:
-- :new_display_name is the name the user wants to change to, in lowercase
-- :current_user_id is the ID of the user making the change
SELECT EXISTS(
SELECT 1
FROM users
WHERE display_name = :new_display_name
AND user_id != :current_user_id
) AS name_taken;
We'd also need queries to update each user settings (changes take effect immediately--there's no final "Update" button in the UI), but these are straightforward.
Finally, if a user chooses to delete their account, we need to rename them to "Deleted User #" where # is the next available number among deleted users, starting from 1. We can do this with this query:
-- :user_id is the ID of the user to delete
WITH next_deleted_number AS (
SELECT (COUNT(*) + 1) AS num
FROM users
WHERE is_deleted = TRUE
)
UPDATE users
SET
display_name = 'deleted user ' || (SELECT num FROM next_deleted_number),
is_deleted = TRUE,
auth_provider = 'none'
WHERE user_id = :user_id;
-- Also clean up other tables
DELETE FROM user_auth
WHERE user_id = :user_id;
DELETE FROM user_settings
WHERE user_id = :user_id;
DELETE FROM user_pawn_settings
WHERE user_id = :user_id;
DELETE FROM user_variant_settings
WHERE user_id = :user_id;
DELETE FROM user_puzzles
WHERE user_id = :user_id;
The actual user record remains in the database to maintain game history and statistics, but the user can no longer log in and their personal information is removed.
Conclusion
This concludes the discussion of the DB schema for the Wall Game, a series of blog posts on building a multiplayer online board game. Next, we'll deep dive into how to train an alpha-zero-like AI for the Wall Game.